import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'Batch Mode
#import pydicom
from pydicom import dcmread
from tempfile import mkstemp
import warnings
warnings.filterwarnings('ignore')Aim: Getting a first impression on the models performance on the given data before going into detailed evaluation
In this case study we demonstrate how misas can give you an overview of the performance of the model by creating plots that show the average dice score of the whole batch of images over different parameters: - Model: ukbb_cardiac network by Bai et al. 2018 [1], trained on UK Biobank cardiac MRI images - Data: Kaggle Data Science Bowl Cardiac Challenge Data MRI images
Prepare Model for Misas
The used model was trained on UK Biobank cardiac imaging data to segment short-axis images of the heart into left ventricle (LV), right ventricle (RV) and myocardium (MY). For details about the model please read the paper (Bai et al. 2018) and cite it if you use it. For implementation, training and usage see the GitHub repository. We downloaded the pre-trained model for short-axis images from https://www.doc.ic.ac.uk/~wbai/data/ukbb_cardiac/trained_model/ (local copy in example/kaggle/FCN_sa). In order to use it with misas we need to wrap it in a class that implements the desired interface (prepareSize and predict taking Image as input, see the main docu for more details).
ukbb_cardiac is written in tensorflow v1. With tensorflow v2 make sure to import the compat module.
The model requires images to be a multiple of 16 in each dimension. We pad images accordingly in prepareSize. Additionally, code in dicom_to_Image takes care of the specifics of transforming a three-channel image into a single-item batch of single-channel images. In predict the output is converted to PIL Image class.
from misas.tensorflow_model import ukbb_model, crop_pad_pilmodel = ukbb_model('example/kaggle/FCN_sa')INFO:tensorflow:Restoring parameters from example/kaggle/FCN_saPrepare Images
Find proper Orientation
We found out, in notebook 02_ukbb_on_kaggle, that prediction is much better if images are prepared properly. However, the images used there, were already converted to png. Now we want to use raw dicoms. The scaling will likely still be the same but orientation might differ. So let’s check with the standard dihedral transformation.
image = "example/kaggle/sample_images/IM-4562-0014.dcm"plot_series(get_dihedral_series(dicom_to_Image(image),model))
def prep_with_dihedral_and_resize(image):
Y,X = image.size
image = crop_pad_pil(image,(int(np.ceil(X / 16.0)) * 16, int(np.ceil(Y / 16.0)) * 16))
image = dihedralTransform(image, 7)
return image.resize((256,256))
model.prepareSize = prep_with_dihedral_and_resizeFor these demonstration purposes, images are selected randomly from all images that have the attributes “Slice Location and”Trigger Time” and that are not automatically generated images that contain plain text or multiple images:
images = [
"example/kaggle/sample_images/IM-13717-0026.dcm",
"example/kaggle/sample_images/IM-7453-0024.dcm",
"example/kaggle/sample_images/IM-4718-0021.dcm",
"example/kaggle/sample_images/IM-5022-0015.dcm",
"example/kaggle/sample_images/IM-14141-0011.dcm",
"example/kaggle/sample_images/IM-13811-0003.dcm",
"example/kaggle/sample_images/IM-4562-0014.dcm"
]Evaluation
If true_masks is “None”, the model will predict a mask for every image, save it as png in a newly created directory and use this mask as truth for the evaluation and afterwards delete the directory and the contained predicted thruths. Thus, it is important to hand in the images in an orientation in which the model makes good predictions, in this case this is handled, by the “prepareImage” function, which reads the dicom file, converts it to a fastai Image object, and rotates and flips the image into correct position
Warning
When mask_prepareSize is set to false, so when no true mask is provided by the user and thus generated by batch_mode, functions that change the size of the true mask like resize don’t work any longer.
batch_results
batch_results (images, model, eval_functions, true_masks=None, components=['bg', 'LV', 'MY', 'RV'])
Evaluation of the models performance across multiple images and transformations
-images (list): paths for dicom files with which the model should be evaluated -model: model to be evaluated -eval_functions (dictionary): keys: name of transformation, values: eval functions from misas.core -true_masks (list, optional): paths of png files with true masks for dicoms in ‘images’ in the same order as ‘images’ -components (list, optional): classes that will be evaluated by the eval functions
Returns: list of Pandas dataFrames, that contains one dataFrame for each image with the columns: ‘parameter’, ‘bg’, ‘LV’, ‘MY’, ‘RV’, ‘File’
truths = []
for i in images:
img = dicom_to_Image(i)
# apply the prepareSize transformation
truth = model.predict(model.prepareSize(img))#[0]
# reverse the rotation from prepareSize as it will be re-applied on the mask before comparison
truth = dihedralTransform(truth, 7)
tmpfile = mkstemp()
truth.save(tmpfile[1] + ".png")
truths.append(tmpfile[1] + ".png")In this example we are passing a list of true masks to the function that will be used for evaluation. Since this is only for demonstration purposes, we will manually generate the list of true masks by predicting the truth for every image and saving it to a temporary directory and storing the path names in a list, from where batch_results can access it.
img = dicom_to_Image(images[0])
truth = model.predict(model.prepareSize(img))#[0]
#tmpfile = mkstemp()
#truth.save(tmpfile[1] + ".png")
#truths.append(tmpfile[1] + ".png")The functions will be passed to batch_results() in a dictionary. The keys are the names of the respective transformations, which will also be used for the title of the final plots. The values are the eval_functions from misas.core. In this case we called them with partial() to edit the parameter nams and start/end/step parameters:
results_with_truths = batch_results(images, model, {
"Rotation": partial(eval_rotation_series, param_name="Degrees"),
"Brightness": partial(eval_bright_series, param_name="Relative Brightness", start=0.025, end=.975, step=0.025),
"Cropping": partial(eval_crop_series, param_name="Image size in Pixels"),
"Contrast": partial(eval_contrast_series, param_name="Relative Contrast", start=0.1, end=4.5, step=0.1),
"Resizing": partial(eval_resize_series, param_name="Pixels", start=20, end=700, step=25),
"Spike Artefact Intensity": partial(eval_spike_series, param_name="Intensity", step=.01, start=0, end=.5),
"Spike Artefact Position": partial(eval_spike_pos_series, param_name="X Position of Spike", step=0.025, intensityFactor=0.2),
"Zoom": partial(eval_zoom_series, param_name="Scale")
}, components=['bg','LV','MY','RV'], true_masks=truths)
dihedral_results_with_truths = batch_results(images, model, {"Orientation": partial(eval_dihedral_series, param_name="Orientation")}, components=['bg','LV','MY','RV'], true_masks=truths)For the dihedral transformation we are storing the evaluation in a separate variable, so we can create a plot that looks different from the others:
In the following we demonstrate that the function can also evaluate the models performance without passing a list of true masks to the function. In this case the model will make a prediction for every image, save it as png and use it as a true mask for evaluation. In this case it is important that the evaluated images are passed to the function in an orientation in which the model can make a good prediction, since this prediction is used as the true mask for all the following transformations. In this case the “right” orientation was evaluated by applying dihedral/rotation transformations to one single example image and evaluating the predictions with misas. Bringing all the images for batch evaluation into this desired orientation is in this case handled by the dicom_to_Image function, but it has to be manually adapted if a different set of data or a different model is used.
results_without_truths = batch_results(images, model, {
"Rotation": partial(eval_rotation_series, param_name="Degrees"),
#"Brightness": partial(eval_bright_series, param_name="Relative Brightness", start=0.025, end=.975, step=0.025),
#"Cropping": partial(eval_crop_series, param_name="Image size in Pixels"),
#"Contrast": partial(eval_contrast_series, param_name="Relative Contrast", start=0.1, end=4.5, step=0.1),
##"Resizing" not supported for batch_mode without a provided truth
#"Spike Artefact Intensity": partial(eval_spike_series, param_name="Intensity", step=.01, start=0, end=.5),
#"Spike Artefact Position": partial(eval_spike_pos_series, param_name="X Position of Spike", step=0.025, intensityFactor=0.2),
#"Zoom": partial(eval_zoom_series, param_name="Scale")
}, components=['bg','LV','MY','RV'])dihedral_results_without_truths = batch_results(images, model, {"Orientation": partial(eval_dihedral_series, param_name="Orientation", mask_prepareSize=False)}, components=['bg','LV','MY','RV'])In this demonstration results_with_truths and results_without_truths is the same because in both cases, the truths are predicted by the model, hence we will continue with the demonstration only with one of the two lists.
Plotting the results
plot_avg_and_dots
plot_avg_and_dots (df, draw_line=True, dots='single_values', value_name='Dice Score')
Plots the average dice score and shows the single data points
Positional arguments: -df (pd.DataFrame object): columns: ‘parameter’, ‘bg’, ‘LV’, ‘MY’, ‘RV’, ‘File’ -draw_line (Boolean): determines if the line between the average of the datapoints is drawn -dots (string): “single_values” or “average”_ determines wether the dots show every single datapoint or one point for the average for each parameter -value_name (str): Name for the Y axis. Depending on which evaluation Score you used in the evaluation function, you can change the Label for the Y axis here.
Returns: altair.FacetChart object
plot_avg_and_errorbars
plot_avg_and_errorbars (df, value_name='Dice Score')
Plots the average dice score and shows the stdev as errorbars.
Positional arguments: -df (pd.DataFrame object): columns: ‘parameter’, ‘bg’, ‘LV’, ‘MY’, ‘RV’, ‘File’ -value_name (str): Name for the Y axis. Depending on which evaluation Score you used in the evaluation function, you can change the Label for the Y axis here.
Returns: altair.FacetChart object
plot_boxplot
plot_boxplot (df, value_name='Dice Score')
Plots the average dice score as boxplots
Positional arguments: -df (pd.DataFrame object): columns: ‘parameter’, ‘bg’, ‘LV’, ‘MY’, ‘RV’, ‘File’ -value_name (str): Name for the Y axis. Depending on which evaluation Score you used in the evaluation function, you can change the Label for the Y axis here.
Returns: altair.FacetChart object
plot_batch
plot_batch (df_results, plot_function=<function plot_avg_and_dots>)
Creates and displays the plots with the data as returned by the batch_results functions.
Positional arguments: -df_results (list): dataframes which contains one dataFrame for each transformation in a format as it is returned by batch_results Keyword arguments: -plot_function: - plot_avg_and_errorbars: plots the average of the dice score of all images across the parameters and shows the standarddeviation as errorbars - plot_avg_and_dots: plots the average of the dice score and additionally shows the single datapoints instead of errorbars - plot_boxplot
Returns: List with altair.FacetChart objects
plots = plot_batch(results_with_truths, plot_avg_and_errorbars)For the dihedral series it does not make any sense to draw the line between the datapoints, hence the results were stored in a seperate variable to be plotted differently:
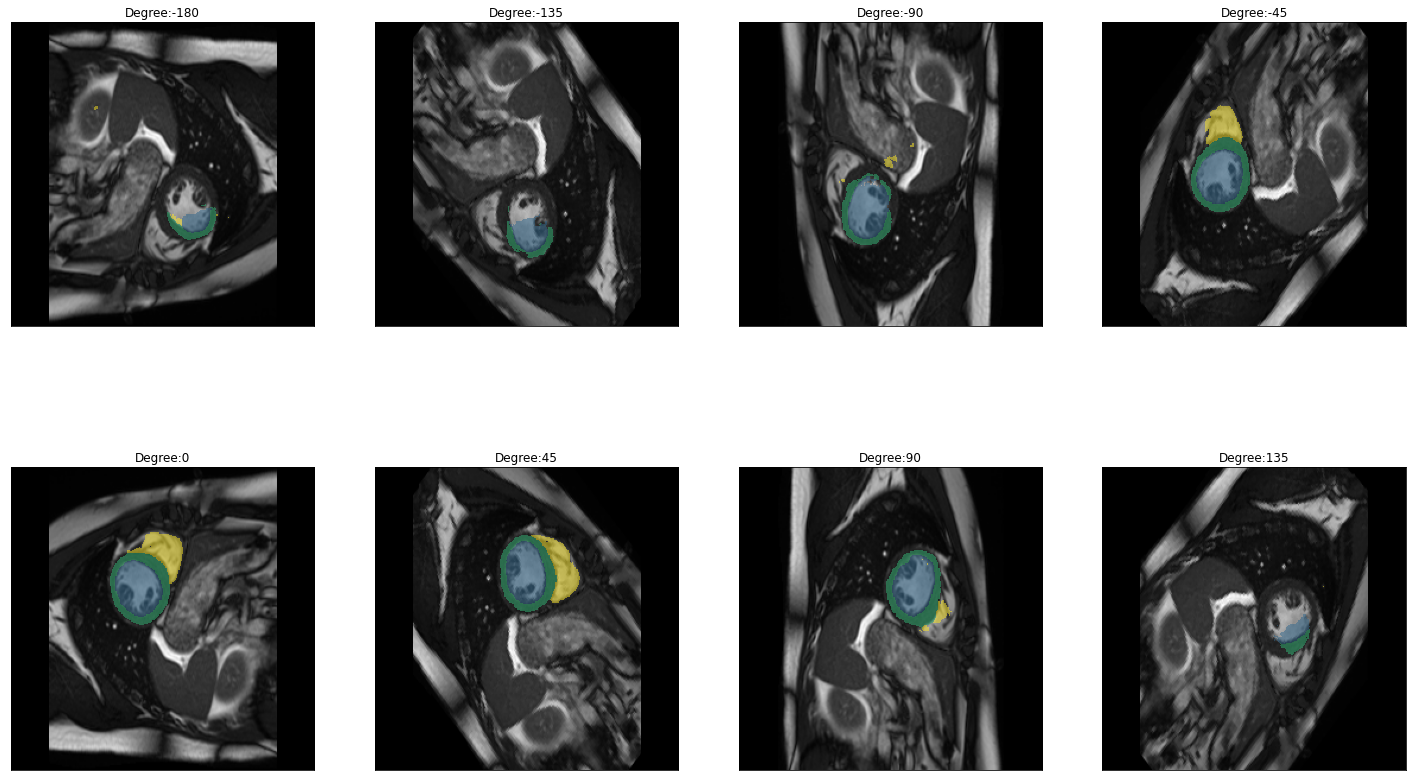
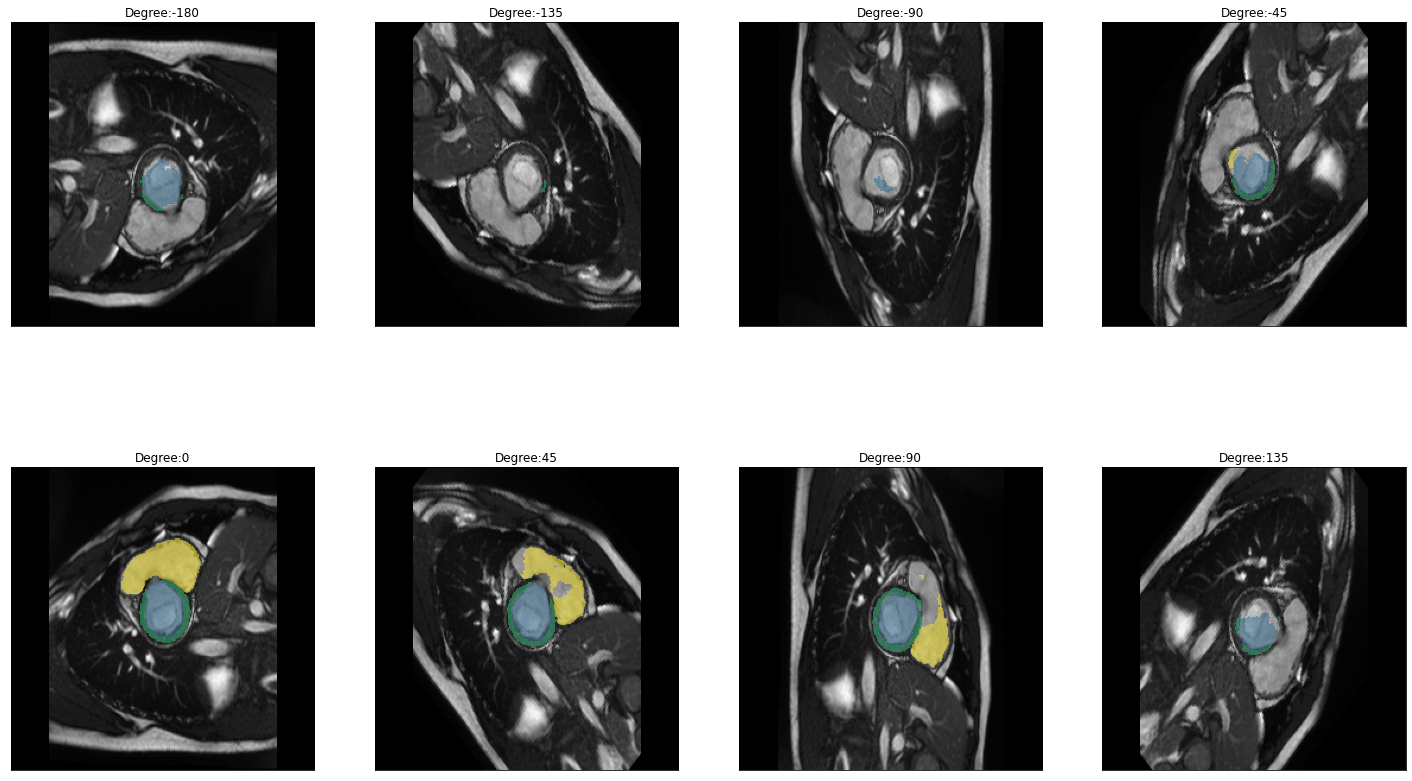
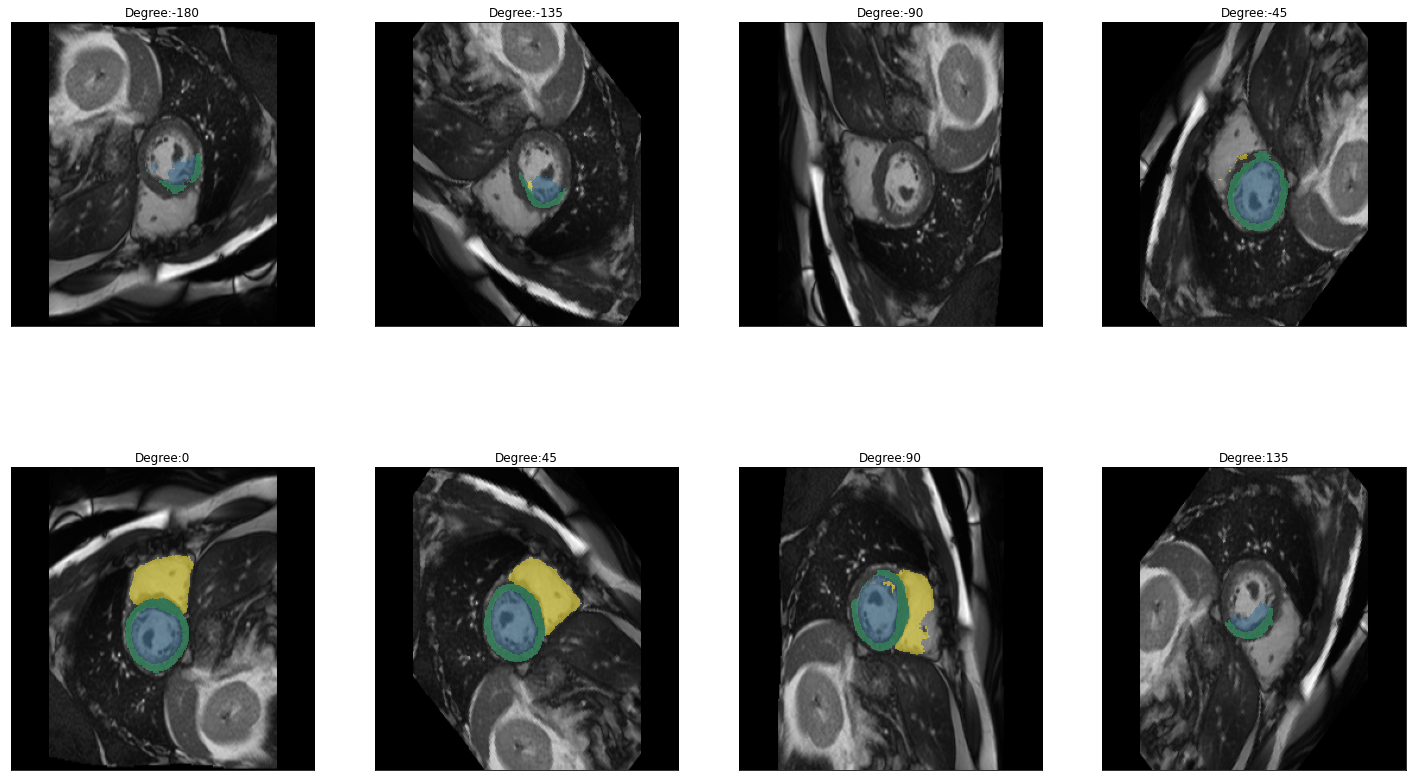
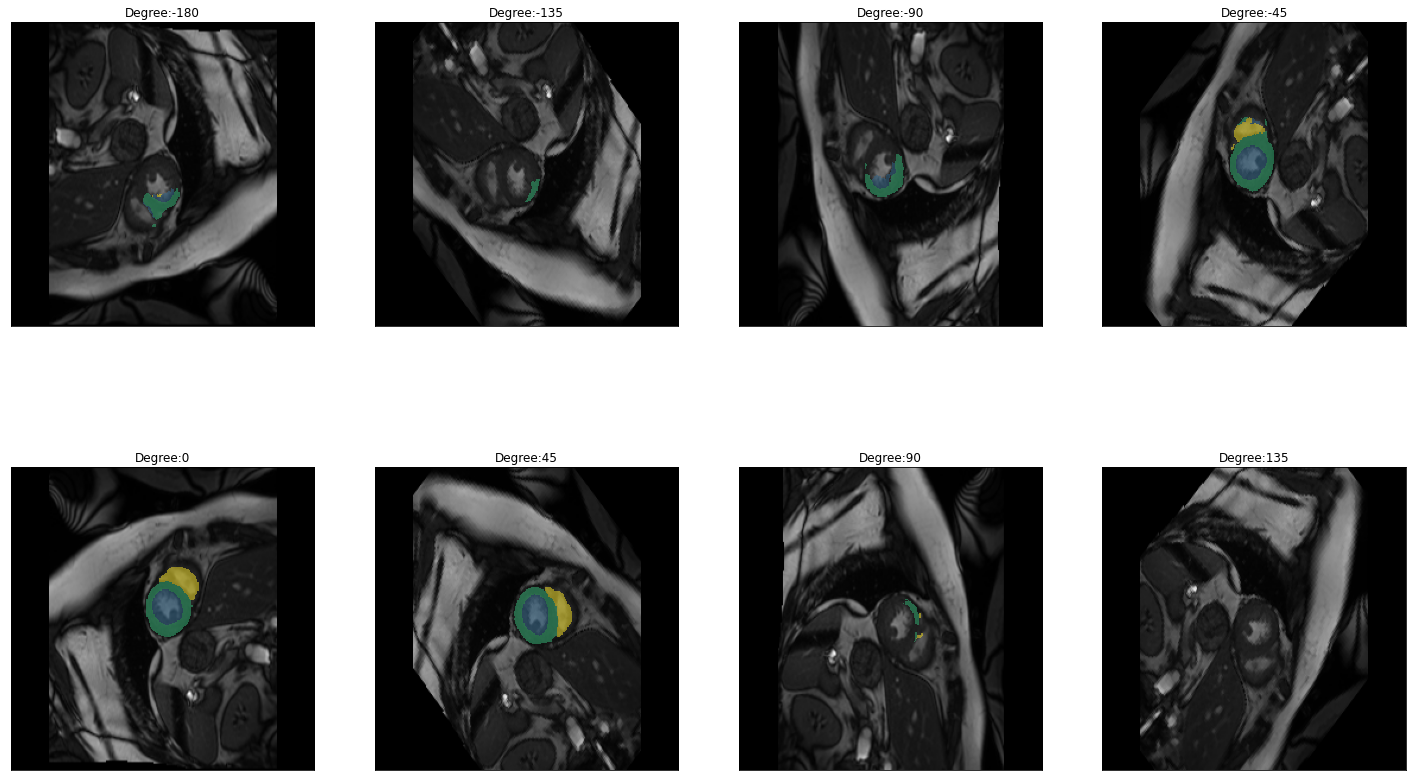
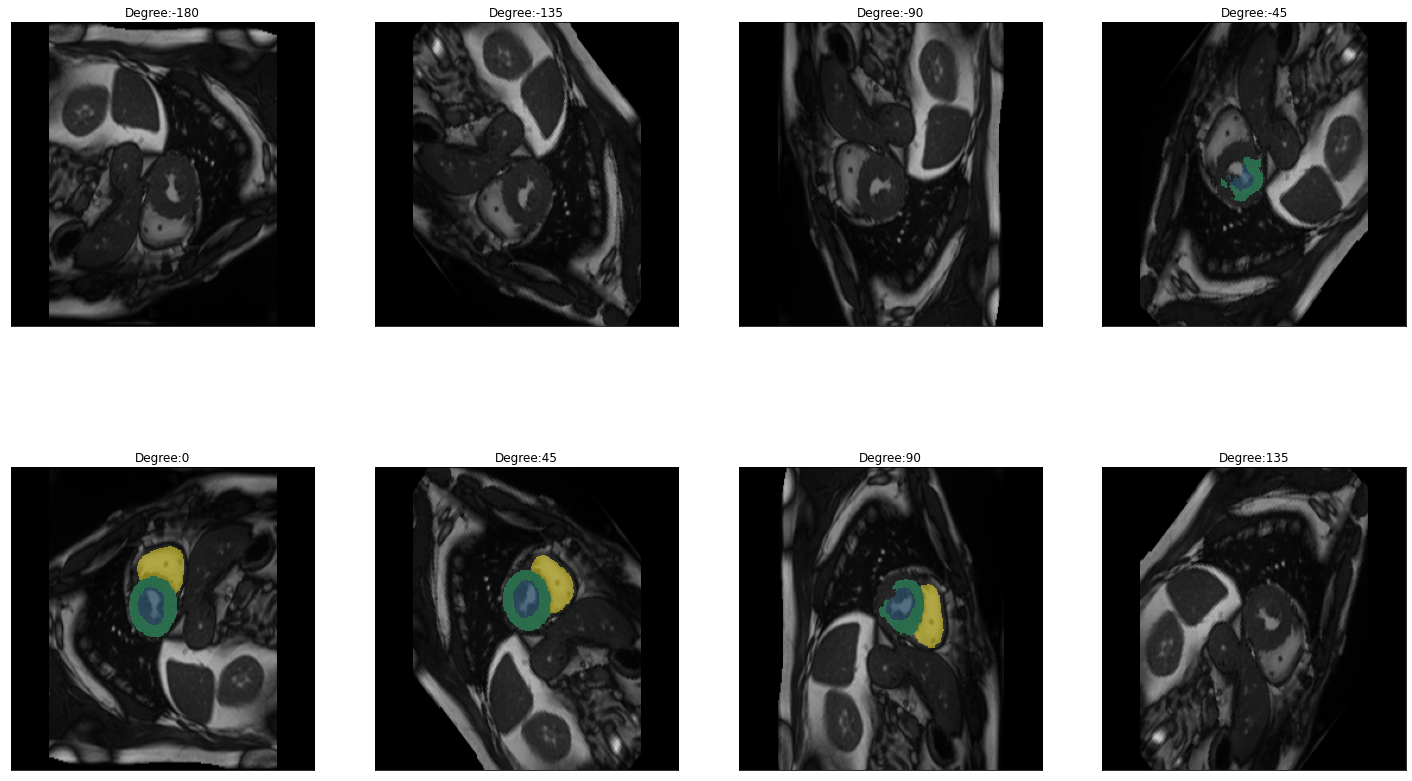
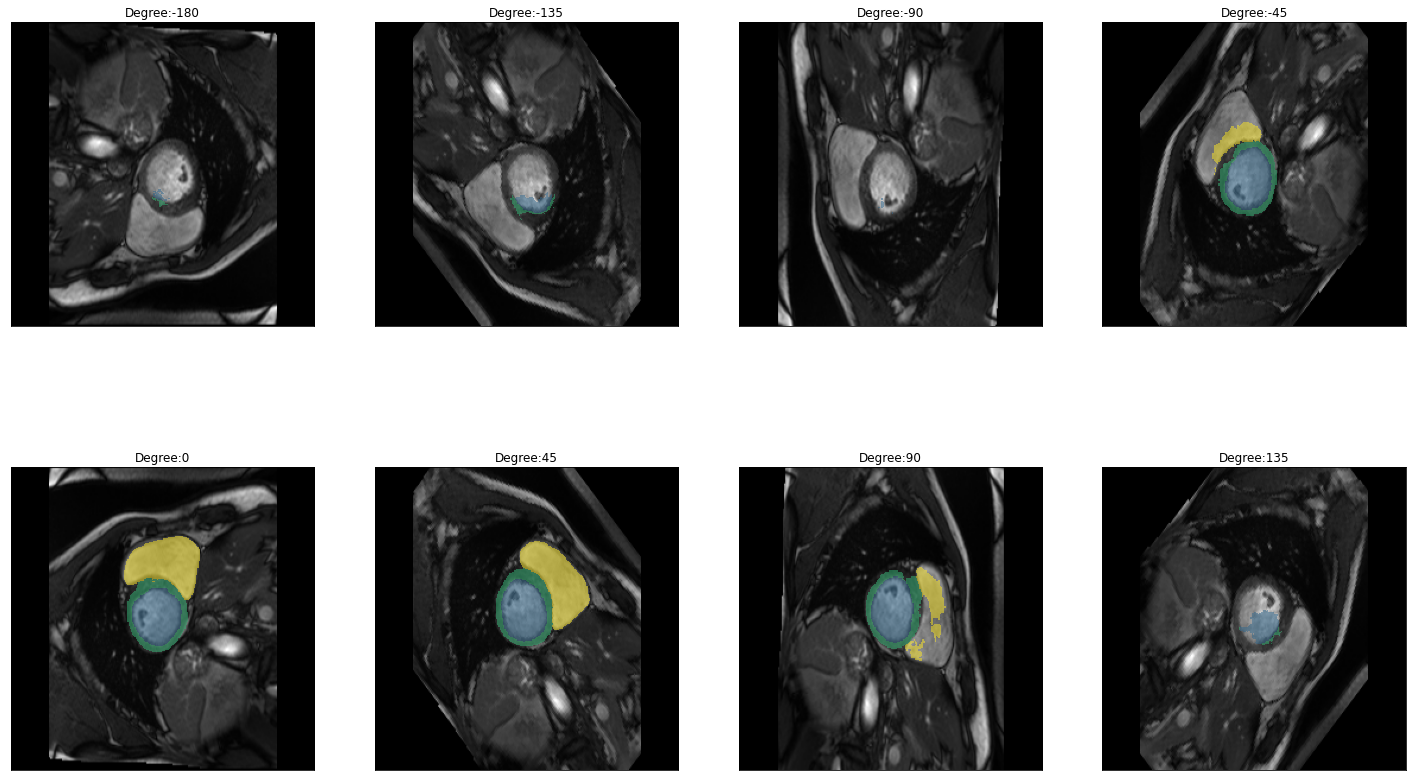
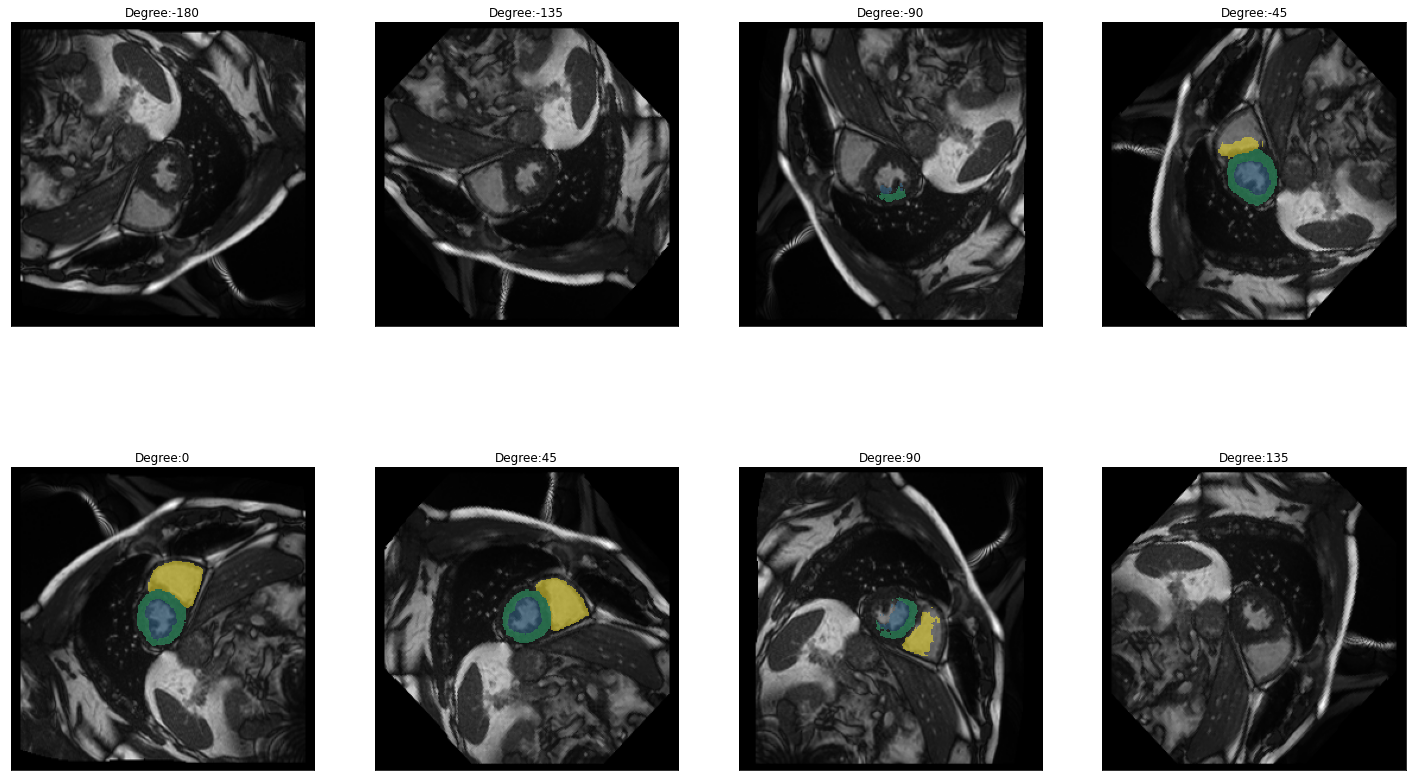
plot_batch(dihedral_results_with_truths, partial(plot_avg_and_dots, draw_line=False, dots="average"))[alt.FacetChart(...)]When calling plot_batch with the parameter partial(plot_avg_and_dots, dots="single_values"), which plots the average plus all the single datapoints, it might look like something went wrong because for some images the dice score seems to be 1 across all parameters. If you look at the images and predictions in detail, like shown below, you can see that for some of the images, the model could not predict any classes, even for the original non-transformed image, which will be used as the truth. Thus, when no prediction can be made for the other transformations the prediction is technically right and results in a dice score of 1. The cause may either be that in the respective images are actually none of the classes present, but the cause can also be, that we are just predicting our truths and it could look different if we used manually created true masks, this has to be kept in mind when interpreting the results.
for i in images:
img = lambda: dicom_to_Image(i)
rotation_series = get_rotation_series(img(), model, start=-180, end=180, step=45) #tfm_y=True
plot_series(rotation_series, nrow=2, figsize=(25,15), vmax=None, param_name='Degree')