from misas.tensorflow_model import ukbb_model, crop_pad_pilCase Study - Model Suitability
Aim: Can I use a given model on a given dataset?
We often find ourselves in a situation where we have a pre-trained model for a certain task (e.g. cardiac segmentation) and we have a data set where we want to perform that task. We know the model was not trained on that specific dataset. So we wonder, how will the model perform? Is it usable at all? Do we need to pre-process our data in a certain way to use it?
In this case study we demonstrate how misas helps answer these questions with a concrete example: - Model: ukbb_cardiac network by Bai et al. 2018 [1], trained on UK Biobank cardiac MRI images - Data: Kaggle Data Science Bowl Cardiac Challenge Data MRI images
Prepare Model for misas
The used model was trained on UK Biobank cardiac imaging data to segment short-axis images of the heart into left ventricle (LV), right ventricle (RV) and myocardium (MY). For details about the model please read the paper (Bai et al. 2018) and cite it if you use it. For implementation, training and usage see the GitHub repository. We downloaded the pre-trained model for short-axis images from https://www.doc.ic.ac.uk/~wbai/data/ukbb_cardiac/trained_model/ (local copy in example/kaggle/FCN_sa). In order to use it with misas we need to wrap it in a class that implements the desired interface (prepareSize and predict taking Image as input, see the main docu for more details).
ukbb_cardiac is written in tensorflow v1. With tensorflow v2 make sure to import the compat module.
model = ukbb_model('example/kaggle/FCN_sa')INFO:tensorflow:Restoring parameters from example/kaggle/FCN_saThe model requires images to be a multiple of 16 in each dimension. We pad images accordingly in prepareSize. Additionally code in image_to_input takes care of the specifics of transforming a three-channel image into a single-item batch of single-channel images. In predict the output is converted to ImageSegment class.
Prepare Dataset for misas
The Data Science Bowl Cardiac Challenge Data consists of MRI cine images from 1140 patients in dicom format. Multiple slices in short axis are available for each patient. Additionally, end-systolic and end-diastolic volumes are given (the original Kaggle challenge asked participants to predict these from the images).
You can download and unpack the dataset from the above website. Some example images are included in the example/kaggle/dicom folder.
We use pydicom to read the images and convert them to pillow Image objects.
from pydicom import dcmread
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from misas.core import default_cmap, default_cmap_true_mask
#import warnings
#warnings.filterwarnings('ignore')We use the window information within the dicom file to scale pixel intensities accordingly.
def prepareImage(fname):
ds = dcmread(fname)
img = (ds.pixel_array.astype(np.int16))
img = (img/img.max()*255).astype(np.uint8)
img = Image.fromarray(np.array(img))
return img.convert("RGB")Okay, let’s look at an example:
img = prepareImage("example/kaggle/117_sax_76_IM-11654-0005.dcm")
plt.imshow(img)
print(np.array(img).shape)(256, 192, 3)
How does the model perform out of the box?
Time to apply the model to the example image and see how it works (we need to call prepareSize manually here):
img = model.prepareSize(img)
fig,ax = plt.subplots(figsize=(8,8))
plt.imshow(img)
pred=model.predict(img)
plt.imshow(pred, cmap=default_cmap, alpha=.5, interpolation="nearest")<matplotlib.image.AxesImage>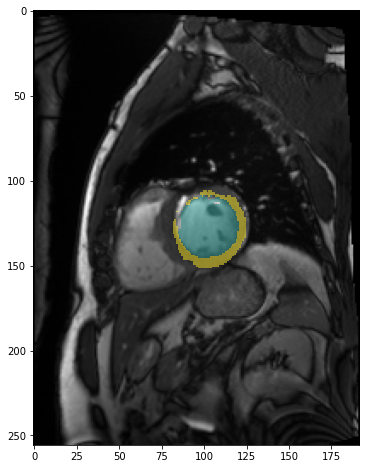
The model identified the left ventricle and myocardium partially. It failed to identify the right ventricle. So this result is promising in that it shows some kind of success but it is not usable as it is.
Note
This is neither surprising nor a critique on the ukbb_cardiac network. That network was trained specifically for UK Biobank images and not to be applied generally.
Still, we might be able to use it on the kaggle dataset if we understand why it fails and properly pre-process the data. This is where misas comes in. But first look at some more examples to see if we selected a bad example by chance.
from glob import globdcm_files = glob("example/kaggle/sample_images/*.dcm")
fig, axs = plt.subplots(2,5, figsize=(20,10))
for i, ax in enumerate(axs.flatten()):
tmp = model.prepareSize(prepareImage(dcm_files[i]))
ax.imshow(tmp)
#model.predict(tmp)[0].show(ax=ax, cmap=default_cmap)
ax.imshow(model.predict(tmp), cmap=default_cmap, vmax=3, alpha=.5, interpolation="nearest")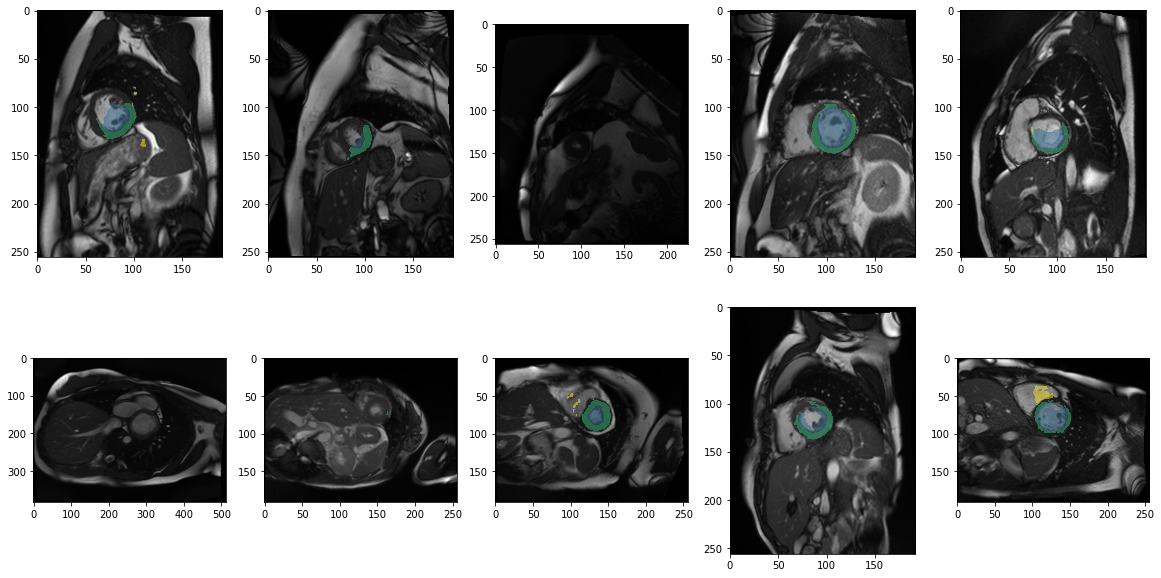
Apparently our first impression that it does not work out of the box applies to most images. This also shows a bit of the variety of images and quality and also some inconsistencies in orientation.
Analysis of one image
In order to get more detailed insights into what’s happening we select a specific example and define two helper functions that will open the image and true mask for that example. We use functions to get the image from file again instead of loading the image once and passing it around to avoid working with an accidentally modified version of the image.
In this case we have the true mask from a previous experiment but it would be possible to create that mask manually as well, it just needs to be saved as png with pixel values 0 for background and 1 to n for the n classes. As there are only three clases in this case looking at the png image in a standard image viewer will look like a purely black image.
from misas.core import *def img():
"""
Opens the sample image as a PIL image
"""
return Image.open("example/kaggle/images/1-frame014-slice006.png").convert("RGB")
def trueMask():
"""
Opens the true mask as a PIL image
"""
return Image.open("example/kaggle/masks_full/1-frame014-slice006.png").convert("I")Sensitivity to orientation
There are eight posible orientations an image can be in (four rotations by 90° and a flipped variant for each). In misas a series with these 8 items is available via get_dihedral_series:
dihedral_series = get_dihedral_series(img(),model, truth=trueMask())plot_series(dihedral_series, nrow=2, figsize=(20,12), param_name="orientation", overlay_truth = True)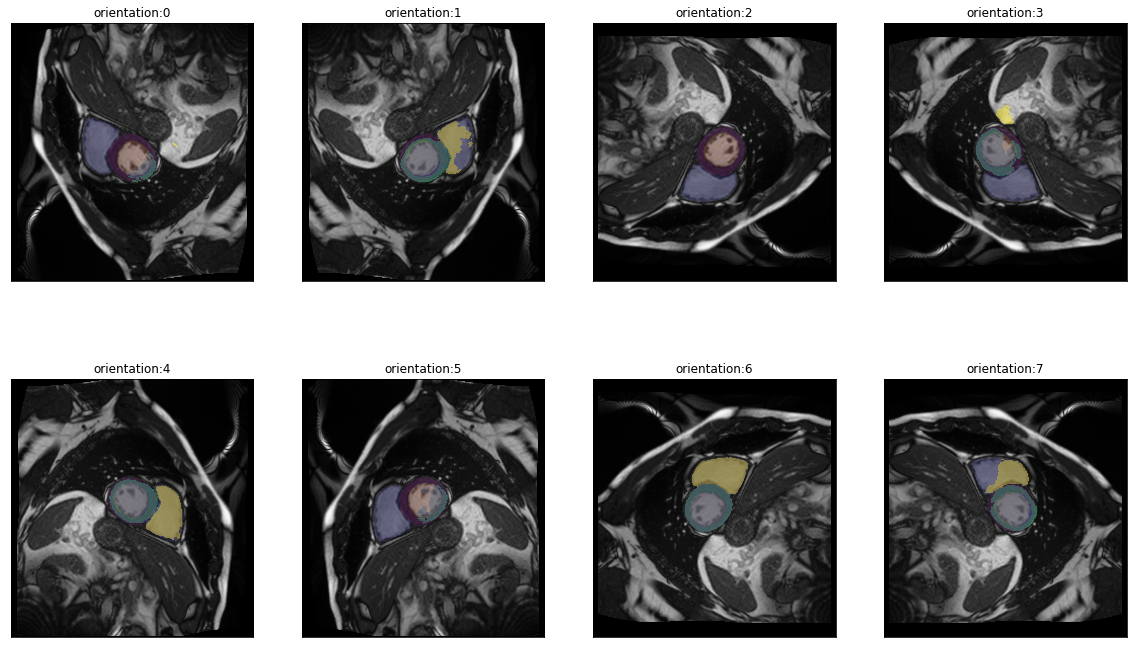
In the default orientation (0) the network is not successful, however when rotated by 90° clockwise (orientation 7) the prediction looks perfect. This can be explained by the different ways the pixel data is stored in the NifTi and DICOM formats. See this page to learn more.
Anyway, as we now know, that (at least for this image) applying a dihedral transformation with parameter 7 yields optimal results we can include this transformation into the preparation function. This way aditional transformations will already use the correctly oriented image as starting point.
def prep_with_dihedral(image):
X, Y = image.size
image=crop_pad_pil(image,(int(np.ceil(X / 16.0)) * 16, int(np.ceil(Y / 16.0)) * 16))
return dihedralTransform(image, 6)model.prepareSize = prep_with_dihedralSensitivity to resize
The next thing that comes to mind when exploring the images from the kaggle dataset is that image size varies (120px-736px). Being fully convolutional, the ukbb_cardiac modell can handle various sizes. Still kernels are trained to work with features of a certain size in pixels so the network cannot be expected to work well with images scaled to arbitrary sizes. Let’s explore:
plot_series(get_resize_series(img(),model, start=50, end=401,step=50), sharex=True, sharey=True, figsize=(20,10), nrow=2)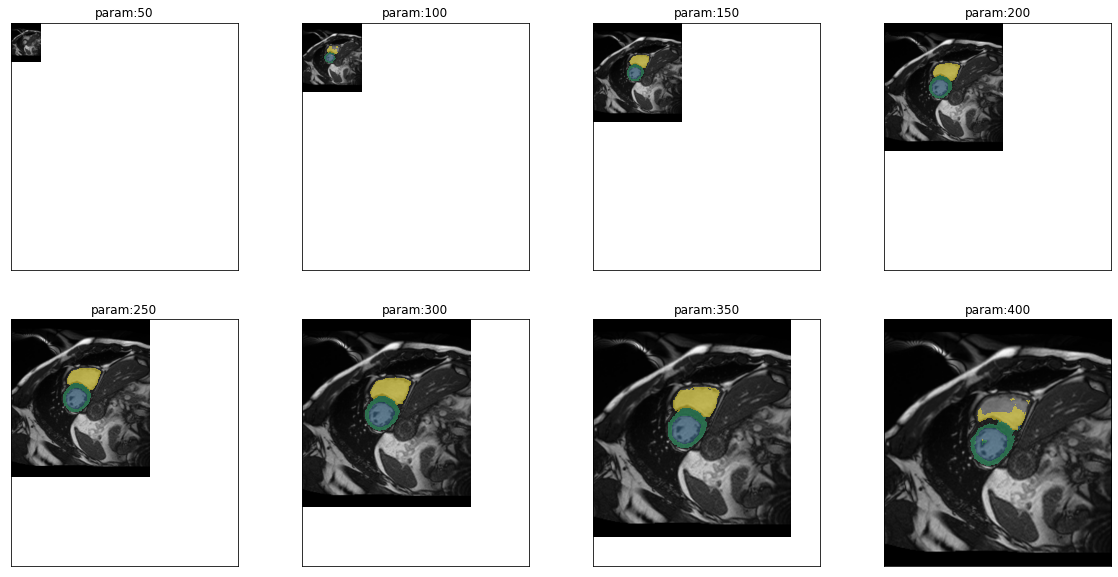
In fact predictions are very good even for small images (100px), they fail on very small images (50px). For large images, performance starts to get worse for right ventricle with images of 350px and for all other classes at 400px. Given the size range of the images in the dataset we have to worry about some of the larger images. But first we want to get a more quantitative view of the performance depending on size. So we can use the ground truth for the first time to calculate dice scores for each class and each parameter value. This can then be visualized as a line graph:
results = eval_resize_series(img(),trueMask(),model,end=600,step=30, components=["bg","LV","MY","RV"])import altair as alt(alt
.Chart(results.melt(id_vars=['px'],value_vars=['LV','MY','RV'],value_name='dice score'))
.mark_line()
.encode(
x="px",
y="dice score",
color="variable",
tooltip="dice score"
)
.properties(width=700,height=300)
.interactive()
)Apparently, there is quite a suitable size range. A size of 256px is well within that range so we can include a resize as part of the preparation:
def prep_with_dihedral_and_resize(image):
image = prep_with_dihedral(image)
return image.resize((256,256))model.prepareSize = prep_with_dihedral_and_resizeSensitivity to rotation
We already know that orientation is really important. So we might wonder how much rotation will be tolerated. Is a rotation by 5° already a problem or will 30° still be fine? We use the same methods as before to address this question:
plot_series(get_rotation_series(img(),model, step=30), nrow=2)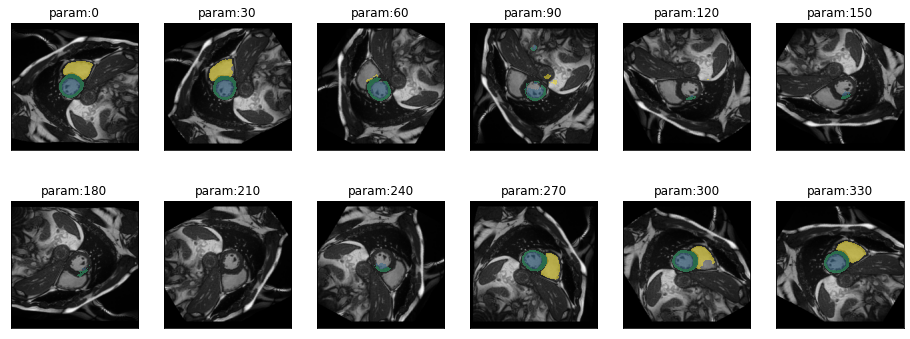
results = eval_rotation_series(img(),trueMask(),model,start=-180,end=180,components=["bg","LV","MY","RV"])(alt
.Chart(results.melt(id_vars=['deg'],value_vars=['LV','MY','RV'],value_name='dice score'))
.mark_line()
.encode(
x="deg",
y="dice score",
color="variable",
tooltip="dice score"
)
.properties(width=700,height=300)
.interactive()
)There is actually quite some tolerance to rotation. But it is not equal in both directions. Rotations by -80° are no problem for this particular image but only rotations up to +40° are possible without loss in performance.
Another tool misas provides to see the effect of a transformation on the prediction more vividly is using gifs:
gif_series(
get_rotation_series(img(),model, start=0, end=360,step=10),
"example/kaggle/rotation_ukbb.gif",
param_name="deg",
duration=400
)
Sensitivity to cropping
Next up is the question of what features the network uses to make predictions? Does it use local features only or does it use the larger context, e.g. surrounding organs? As long as the region of interest is at the center of the image we can answer this question by successively cropping more and more contend from the border:
plot_series(get_crop_series(img(),model, start = 0, step = 10, end=120), nrow=2)results = eval_crop_series(img(),trueMask(),model,start = 5, components=["bg","LV","MY","RV"])(alt
.Chart(results.melt(id_vars=['pixels'],value_vars=['LV','MY','RV'],value_name='dice score'))
.mark_line()
.encode(
x="pixels",
y="dice score",
color="variable",
tooltip="dice score"
)
.properties(width=700,height=300)
.interactive()
)This analysis indicates that not a lot of context is required for the network to reliably detect the heart (as long as at least the full left ventricle is part of the image). The dice score of 1.0 for MY and RV for very small sizes is due to the fact that the model does not predict anything and indeed there is no MY or RV left on the image. It remains 0.0 for LV as there is always LV on the center crop.
gif_series(
get_crop_series(img(),model, start=5, end=120,step=10),
"example/kaggle/crop_ukbb.gif",
param_name="pixels",
duration=400
)
Sensitivity to brightness
Next let’s see if the network is very sensitive to brightnes or contrast which would suggest some kind of pre processing, e.g. adaptive histogram equalization
plot_series(get_brightness_series(img(),model, start=0.25, end=4*np.sqrt(2), step=np.sqrt(2),log_steps = True), nrow=2, figsize=(12,6)) #nrow=2)results = eval_bright_series(img(),trueMask(),model, end = 8, components=["bg","LV","MY","RV"])(alt
.Chart(results.melt(id_vars=['brightness'],value_vars=['LV','MY','RV'],value_name='dice score'))
.mark_line()
.encode(
x="brightness",
y="dice score",
color="variable",
tooltip="dice score"
)
.properties(width=700,height=300)
.interactive()
)gif_series(
get_brightness_series(img(),model, start=0.25, end=8, step=np.sqrt(2),log_steps = True),
"example/kaggle/bright_ukbb.gif",
param_name="brightness",
duration=400
)
The network seems to be quite robust to differences in brightness.
Sensitivity to contrast
plot_series(get_contrast_series(img(),model, start=0.25, end=8, step=np.sqrt(2),log_steps = True))results = eval_contrast_series(img(),trueMask(),model, end = 2.5, step= 0.3, components=["bg","LV","MY","RV"])(alt
.Chart(results.melt(id_vars=['contrast'],value_vars=['LV','MY','RV'],value_name='dice score'))
.mark_line()
.encode(
x="contrast",
y="dice score",
color="variable",
tooltip="dice score"
)
.properties(width=700,height=300)
.interactive()
)gif_series(
get_contrast_series(img(),model, start=0.25, end=8, step=np.sqrt(2),log_steps = True),
"example/kaggle/contrast_ukbb.gif",
param_name="contrast",
duration=400
)
The network seems to be quite robust to differences in contrast.
References
[1] W. Bai, et al. Automated cardiovascular magnetic resonance image analysis with fully convolutional networks. Journal of Cardiovascular Magnetic Resonance, 20:65, 2018.
Supplemental Information
If you have the full kaggle dataset you can draw a random sample using this code (omit the seed to really make it random)
#nbdev_fulldata_test
# As we cannot include the whole kaggle dataset in the repo I draw a sample like this:
from glob import glob
from shutil import copy
import os
import random
random.seed(42)
dcm_files = glob("kaggle/train/*/sax_*/*.dcm")
os.makedirs('example/kaggle/sample_images', exist_ok=True)
for f in random.sample(dcm_files,20):
copy(f, 'example/kaggle/sample_images')